EDA (탐색적 데이터 분석)란?
- 데이터 분석을 수행하기 전에 데이터의 구조를 파악하고 특성을 이해하는 과정
- EDA를 통해 데이터의 패턴을 발견하고, 이상치 및 결측치를 확인하여 적절한 전처리 방법을 결정
EDA 데이터 분석 절차
1. 데이터 로드 및 기본 정보 확인 (API, CSV, SQL)
2. 결측치 및 이상치 탐색
3. 기술통계를 활용한 데이터 요약 (기술 = description)
4. 변수 간 관계 분석 및 시각화
5. 결론 도출 및 마케팅 전략 수립 → 보고서
1. 데이터 로드 및 데이터의 기본 정보 파악
데이터 셋 불러오기 (CSV), 데이터의 크기, 컬럼명, 데이터 타입 확인
import pandas as pd
# 데이터 로드 (예제 데이터)
df = pd.read_csv("sample_data.csv")
# 데이터 크기 확인 (행, 열 개수)
print(f"데이터 크기: {df.shape}")
# 컬럼명 확인
print(f"컬럼명: {df.columns.tolist()}")
# 데이터 타입 확인
print(df.info())
# 상위 5개 행 출력
print(df.head())
2. 결측치 및 이상치 탐색
누락된 값(결측치)와 비정상적인 값(이상치)를 찾아 적절한 처리방안 결정
결측치 확인
# 각 컬럼별 결측치 개수 확인
print(df.isnull().sum())
평균과 중앙값으로 결측치 대체하고 결측치 있는지 다시확인
# 평균으로 대체
df['나이'] = df['나이'].fillna(df['나이'].mean())
# 최빈값으로 대체
df['소득'] = df['소득'].fillna(df['소득'].median())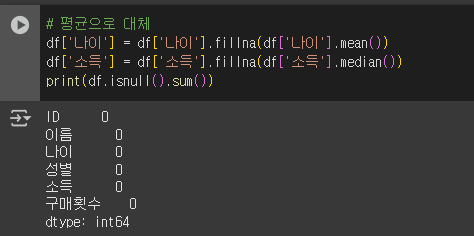
이상치 탐색
탐색방법 :
박스플롯 활용 - 사분위수를 기반으로 이상치를 탐색
Z-score 활용 - 데이터가 평균에서 얼마나 벗어났는지 확인
박스플롯 활용
import matplotlib.pyplot as plt
import seaborn as sns
# 박스플롯으로 이상치 확인
plt.figure(figsize=(6, 4))
sns.boxplot(x=df['소득'])
plt.title("소득 이상치 탐색")
plt.show()
한글이 깨지는 문제는 !pip install koreanize-matplotlib 입력하여 설치
실행은 import koreanize_matplotlib 입력
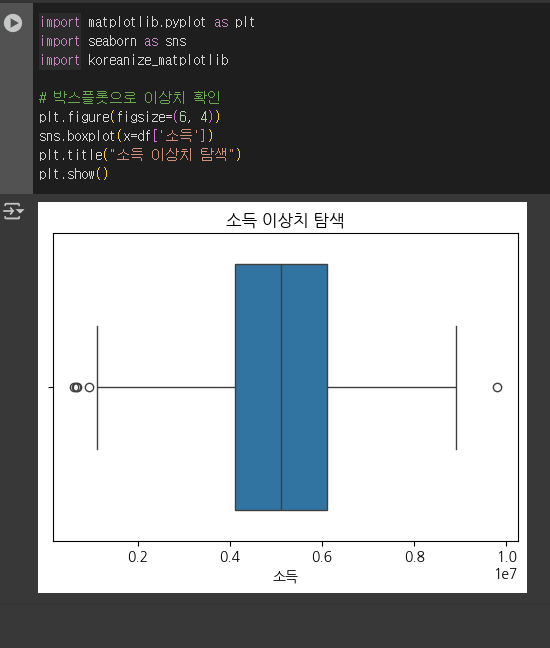
박스플롯 보는 방법 (from ChatGPT)

Z-score 활용
from scipy import stats
# Z-score 계산
df["소득_Z"] = stats.zscore(df["소득"])
# Z-score가 3 이상인 데이터 조회
outliers = df[df["소득_Z"].abs() > 3]
print(outliers)
3. 기술통계를 활용한 데이터 요약
데이터의 중심 경향 (평균, 중앙값, 최빈값)과 산포도(분산, 표준편차)를 분석하여 데이터의 특성을 파악.
방법 :
1) 히스토그램으로 데이터 분포 확인 ( 히스토그램으로 빈도수 확인)
2) 평균, 중앙값, 최빈값, 표준편차 등을 분석
히스토그램을 이용한 데이터 분포 확인
plt.figure(figsize=(6, 4))
sns.histplot(df["소득"], bins=30, kde=True)
plt.title("소득 분포")
plt.show()
QQ-Plot을 이용한 정규성 확인

점들이 직선에 가까우면 정규성을 띄고 있음을 의미함.
정규성은 데이터가 정규분포를 따르는 정도를 의미함.
정규분포는 평균을 중심으로 데이터가 퍼져 있고, 평균 근처에 값이 많고, 극단적인 값은 적은 형태를 띤다.
4. 변수 간 관계 분석 및 시각화
변수 간 관계를 확인하면 데이터의 패턴을 파악하는데 도움이 됨.
상관계수 확인 - 변수 간의 관계 파악
# 수치형 변수 간의 상관계수 확인
correlation_matrix = df.select_dtypes(include=[float, int]).corr()
print(correlation_matrix)
현재 데이터에서는 어떤 변수도 서로 유의미한 상관관계를 가지지 않음!
※ 상관계수(Correlation Coefficient)란?
- 두 수치형 변수 간의 선형 관계를 나타내는 값
- 값의 범위:
- +1 → 강한 양의 상관관계 (한 변수가 증가하면 다른 변수도 증가)
- 0 → 상관관계 없음 (변수 간 연관성이 없음)
- -1 → 강한 음의 상관관계 (한 변수가 증가하면 다른 변수는 감소)
상관 행렬 히트맵 시각화
plt.figure(figsize=(8, 6))
sns.heatmap(correlation_matrix, annot=True, cmap="coolwarm", fmt=".2f")
plt.title("상관관계 히트맵")
plt.show()
1에 가까울수록 양의 상관관계, -1에 가까울수록 음의 상관관계
산점도를 활용한 관계 분석 (변량이 많을때, 2차원 벡터를 시각화)
plt.figure(figsize=(6, 4))
sns.scatterplot(x=df["소득"], y=df["구매횟수"])
plt.xlabel("소득")
plt.ylabel("구매횟수")
plt.title("소득과 구매횟수 관계")
plt.show()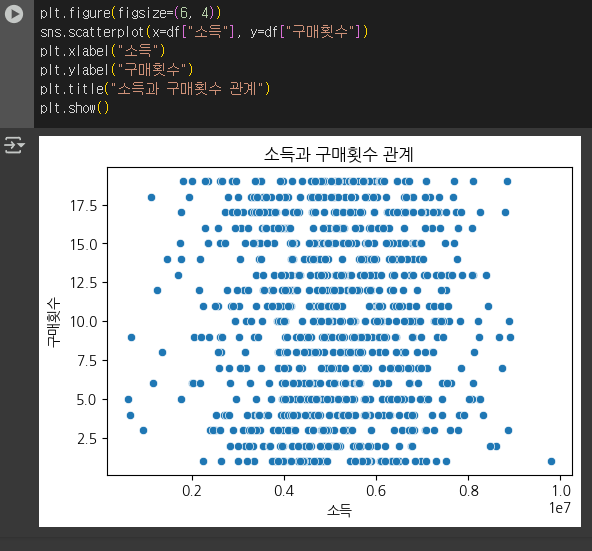
점들이 특정 패턴을 보이면 두 변수 간 관계가 있다고 볼 수 있음.
위에서는 소득과 구매횟수간 상관관계를 찾기 어렵다.
범주형 변수 분석
plt.figure(figsize=(6, 4))
sns.boxplot(x=df["성별"], y=df["소득"])
plt.title("성별에 따른 소득 분포")
plt.show()
범주형 변수(성별)와 수치형 변수(구매금액)의 관계를 분석할 때 박스플롯 활용
데이터 정리 및 이상치 제거
# 이상치 제거 (소득이 Z-score 3 초과인 데이터 제거)
df_cleaned = df[df["소득_Z"].abs() <= 3]
# 필요 없는 컬럼 제거 (Z-score 컬럼 삭제)
df_cleaned = df_cleaned.drop(columns=["소득_Z"])
print(df_cleaned.info()) # 데이터 정리 후 구조 확인
※ 어디에 무슨 그래프를 써야하나 ?
두개 이상의 변량일 때 → 산점도 (2차원 벡터)
분포 → 히스토그램
이상치를 확인 → 박스플롯
비교할 때는 → 바차트
과거 데이터와 함께 볼 때, 과거와 현재의 변화 파악, 시간대별 변화 → 선 그래프
비율 분석 → 파이차트
그래프 시각화하는 코드는 필요할 때 코드 패턴 복사
5. 결론 도출 및 마케팅 전략 수립 → 보고서 (실습)
EDA를 활용한 데이터 분석과 그로스 마케팅 관점의 접목
데이터를 기반으로
1. 고객 행동 분석
2. 전환율 최적화
3. 마케팅 ROI 분석
을 수행해야 한다.
※ ROI(투자 수익률)은 투자 대비 얼마나 수익을 얻었는지를 나타내는 비율
고객의 행동패턴을 시각적으로 분석하고 인사이트를 도출(특징)해야 한다.
기억하기
.unique() 함수는 특정 컬럼에 존재하는 고유한 값(중복되지 않은 값)을 반환할 때 사용
< 리눅스 파일 권한 (읽기, 쓰기, 실행)과 숫자 표현 >
| 권한 | 기호 표현 | 숫자 값 |
| 읽기 | r (read) | 4 |
| 쓰기 | w (write) | 2 |
| 실행 | x (execute) | 1 |
여러 권한을 조합할 때는 숫자를 더한다.
| 숫자 | 권한 | 설명 |
| 0 | --- | 아무 권한 없음 |
| 1 | --x | 실행만 가능 |
| 2 | -w- | 쓰기만 가능 |
| 3 | -wx | 쓰기 + 실행 가능 (2+1) |
| 4 | r-- | 읽기만 가능 |
| 5 | r-x | 읽기 + 실행 가능 (4+1) |
| 6 | rw- | 읽기 + 쓰기 가능 (4+2) |
| 7 | rwx | 읽기 + 쓰기 + 실행 가능 (4+2+1) |

명령어로 monday폴더에 읽기와 쓰기 권한을 부여한 모습
'데이터 분석 part' 카테고리의 다른 글
| 회귀분석 (단순회귀분석과 다중회귀분석) (1) | 2025.02.25 |
|---|---|
| 통계의 기본개념 (0) | 2025.02.21 |
| 그로스 마케팅에서의 그래프 사용, 데이터 변환의 중요성 (0) | 2025.02.19 |
| Pandas 복습과 설문조사 개요, 설문조사 후 데이터 분석, 시각화 (2) | 2025.02.18 |
| API의 개념과 API 데이터 수집 (1) | 2025.02.17 |