머신러닝은 전통적인 프로그래밍 방식과는 달리 명시적인 규칙을 프로그래머가 지정하는 것이 아니라, 알고리즘(계산방식)이 데이터를 분석하여 스스로 규칙을 찾아내는 방식으로 동작한다.
머신러닝의 정의
- 데이터에서 패턴을 찾아 학습하고, 새로운 데이터에 대해 예측을 수행하는 시스템
# 회귀식으로 머신러닝의 기본 개념 이해하기
1)
Y = W * X
- Y → 라벨, 예측하려는 값, 출력(Output, 종속변수)
- X → 입력 데이터, 학습데이터 (Input, 독립변수)
- W → 가중치(Weight) 또는 계수(Coefficient), 모델, 패턴, 모델이 학습해야 할 값
☞ '입력 데이터(X)'에 어떤 '가중치(W)'를 곱해서 '출력(Y)'을 예측하는 것!
즉, 머신러닝 모델은 적절한 W(가중치)를 찾는 과정.
머신러닝 목표:
= W를 잘 조정해서, X가 들어왔을 때 정확한 Y를 예측하는 모델을 만드는 것.
= Y(예측값) - Y(실제값) 차이를 최소화하는 방향으로 W를 조정
2) 조금 더 정확한 수식 :
Y = W0 + W1*X1 + W2*X2 +...+ Wn*Xn
- W₀ (Bias, 편향): 데이터를 이동시키는 역할을 하는 상수값, 절편
- W₁, W₂, ..., Wₙ (Weight, 가중치): 각 입력값(X)에 곱해지는 값, 기울기
머신러닝 모델은 X 값들을 넣었을 때, 실제 Y 값과 가장 비슷한 값을 예측할 수 있도록 W를 찾아가는 과정을 수행.
3) 머신러닝 학습 과정
- X(입력)와 Y(정답)를 준비
- 초기 W 값을 랜덤하게 설정
- X에 W를 곱해서 Y를 예측
- 예측값과 실제값(Y)의 차이(오차)를 계산
- 오차를 줄이도록 W를 업데이트 - 최적화 (ex: 경사 하강법 사용)
- 이 과정을 반복해서 W를 최적의 값으로 학습
- 이제 새로운 X가 들어오면 Y를 예측할 수 있음.
4) 지도학습(Supervised Learning)과의 관계
- 지도학습에서는 정답(Y)이 존재하기 때문에, 학습 과정에서 Y가 될 수 있도록 W를 찾는 과정을 반복.
- 만약 Y(정답)가 없다면? 비지도학습이 되고, 여기서는 W를 직접적으로 찾지 않고, 데이터의 패턴을 분석하는 게 목표이다. 정답(Y)이 없으니까, 단순히 비슷한 특징을 가진 것끼리 묶는 방식(군집화)으로 학습함.
5) 딥러닝에서는 Y = W * X를 좀 더 확장한 형태를 사용.
- 딥러닝에서는 뉴런(Neuron)이 여러 개 있어서 비선형 함수(활성화 함수)도 추가됨.
- 기본 구조는 Y = W * X지만, 여기에 여러 층(layer)과 비선형 변환이 추가.
6) 딥러닝과 머신러닝의 차이
- 머신러닝: 데이터에서 패턴을 학습하는 모든 방법을 포함하는 큰 개념. 사람이 특징을 직접 설계하고(W를 조정하는 규칙을 사람이 일부 정함), 모델을 학습하는 방식
- 딥러닝: 머신러닝의 한 종류로, 신경망(Neural Network)을 이용해 특징(Feature)까지 자동으로 학습하는 방법. W뿐만 아니라 특징(Feature)까지 자동으로 학습하는 방식. 즉, 사람이 설계하는 부분이 줄어듦.
| 머신러닝 | 딥러닝 | |
| 지도학습 가능? | 가능 | 가능 |
| 비지도학습 가능? | 가능 | 가능 |
| 특징 설계 | 사람이 직접 설계 | 모델이 자동으로 학습 |
| 복잡한 데이터 처리 | 상대적으로 어려움 | 가능 (이미지, 음성, 텍스트 등) |
머신러닝의 주요 학습 유형
1) 지도 학습 (교사학습)
- 정의: 입력 데이터(특징, Feature)와 이에 대응하는 정답(레이블, Label)이 주어진 상태에서 학습하는 방식
- 목표: 주어진 데이터를 기반으로 입력과 출력 간의 관계를 학습하여, 새로운 입력값에 대해 올바른 출력을 예측하는 것
- 예제
- 이메일이 스팸인지 아닌지를 분류하는 모델
- 주어진 집의 특성을 보고 가격을 예측하는 모델
- 대표 알고리즘 - 1. 분류 2. 예측
- 선형 회귀(Linear Regression)
- 로지스틱 회귀(Logistic Regression)
- 의사결정나무(Decision Tree)
- 랜덤 포레스트(Random Forest)
- 서포트 벡터 머신(SVM)
- 신경망(Neural Networks, 딥러닝)
2) 비지도 학습(비교사학습)
- 정의: 정답(레이블)이 없는 데이터에서 패턴을 찾는 방식
- 목표: 데이터의 구조를 이해하고 그룹을 발견하거나 특징을 요약하는 것 (데이터의 같은 특성끼리 그룹핑)
- 예제
- 고객을 유사한 그룹으로 묶는 고객 세분화(Clustering)
- 문서를 주요 주제로 분류하는 토픽 모델링(Topic Modeling)
- 대표 알고리즘
- 군집화(Clustering): K-평균(K-Means), DBSCAN, 계층적 군집화
- 차원 축소(Dimensionality Reduction): PCA(주성분 분석), t-SNE, UMAP
3) 강화 학습
- 교사학습의 변동
- 정의: 에이전트(Agent)가 환경(Environment)과 상호작용하면서 보상(Reward)을 최대화하는 방식으로 학습하는 방법
- 목표: 최적의 행동(Policy, 정책)을 학습하여 주어진 환경에서 높은 보상을 받도록 하는 것
- 예제
- 게임 플레이 AI(알파고, DQN)
- 로봇의 행동 제어
- 자율주행 차량의 최적 경로 찾기
- 대표 알고리즘
- Q-러닝(Q-Learning)
- 심층 강화 학습(Deep Q-Network, DQN)
- 정책 기반 학습(Policy Gradient)
※ 강화학습의 예 : 강아지(에이전트)를 주인이 훈련시키려고 할 때는 정책(벌칙과 보너스)을 가지고 한다.
강아지가 지정된 장소에 응가하면 뼈다귀(보너스)를 주고, 안 그러면 몽둥이(벌칙).
머신러닝의 주요 개념
1) 데이터셋 (Dataset)
머신러닝 모델을 학습시키기 위해 필요한 데이터의 모음.
- 훈련 데이터(Training Data): 모델을 학습시키기 위한 데이터
- 검증 데이터(Validation Data): 학습 과정에서 모델의 성능을 평가하는 데이터
- 테스트 데이터(Test Data): 학습이 끝난 후 모델의 최종 성능을 평가하는 데이터
2) 특징(Feature)과 라벨(Label)
- 특징(Feature): 입력 데이터의 속성을 나타내는 변수(예: 키, 몸무게, 연령) - 독립변수(X)
- 레이블(Label): 예측해야 하는 값(예: 암 진단 여부, 집값) - 종속변수(Y)
3) 과적합(Overfitting)과 과소적합(Underfitting)
- 기준점 : 특징
- 과적합(Overfitting): 학습 데이터에는 잘 맞지만 새로운 데이터에는 성능이 떨어지는 현상

- 과소적합(Underfitting): 모델이 데이터의 패턴을 충분히 학습하지 못한 경우
- 해결 방법:
- 과적합 방지: 정규화(Regularization), Dropout, 데이터 증강(Data Augmentation)
- 과소적합 해결: 모델 복잡도 증가, 데이터 추가
4) 손실 함수(Loss Function)와 최적화(Optimization)
- 실제값과 추정값을 뺀 값이 0으로 수렴하게 하는 과정
- 손실 함수: 모델이 예측한 값(y추정값)과 실제 값(y값) 간의 차이를 측정하는 함수
- 최적화 기법: 손실을 최소화하도록 모델을 개선하는 방법 (예: 경사 하강법)
머신러닝의 주요 알고리즘
1) 회귀(Regression)
- 연속적인 값을 예측하는 문제 (예: 주택 가격 예측)
- 대표 알고리즘: 선형 회귀(Linear Regression), 다항 회귀(Polynomial Regression)
2) 분류(Classification)
- 카테고리 값을 예측하는 문제 (예: 이메일 스팸 분류)
- 대표 알고리즘: 로지스틱 회귀, 결정 트리, 랜덤 포레스트, SVM (※ 신경망이 더 성능 ↑)
3) 군집화(Clustering)
- 유사한 데이터를 그룹으로 묶는 문제 (예: 고객 세분화)
- 대표 알고리즘: K-평균, DBSCAN
머신러닝 모델 평가 방법
머신러닝 모델이 얼마나 잘 동작하는지 평가하기 위한 다양한 지표
1) 회귀 평가 지표
- 평균 제곱 오차(MSE): 예측값과 실제값 간의 차이의 제곱 평균
- 평균 절대 오차(MAE): 예측값과 실제값 간의 절대값 차이 평균
- R²(결정 계수): 모델이 데이터를 얼마나 잘 설명하는지 나타내는 지표
2) 분류 평가 지표
- 정확도(Accuracy): 전체 데이터 중 올바르게 분류된 비율
- 정밀도(Precision): 모델이 양성으로 예측한 데이터 중 실제 양성 비율
- 재현율(Recall): 실제 양성 데이터 중 모델이 양성으로 예측한 비율
- F1-Score: 정밀도와 재현율의 조화 평균
머신러닝의 응용 분야
1) 자연어 처리(NLP) - 감성 분석, 챗봇, 기계 번역
2) 컴퓨터 비전 - 얼굴 인식, 자율주행, 객체 탐지
3) 추천 시스템 - 영화 추천, 제품 추천
4) 금융 및 헬스케어 - 사기 탐지, 암 진단
머신러닝 학습을 위한 필수 도구 및 라이브러리
- Python: 머신러닝에 가장 많이 사용되는 언어
- NumPy, pandas: 데이터 전처리 및 분석
- scikit-learn: 다양한 머신러닝 알고리즘 제공
- TensorFlow, PyTorch: 딥러닝 프레임워크
※ TensorFlow 는 구글에서 만든 머신러닝 프레임워크, PyTorch는 파이썬에서 만든 프레임워크
※ 함수와 함수가 모이면 라이브러리, 라이브러리와 라이브러리가 모이면 프레임워크.
머신러닝 학습 과정 요약
- 문제 정의 및 목표 설정
- 개발 범위(어떤 문제를 해결할 것인지)를 정한다.
- 종속변수(Y, 예측하고 싶은 값)를 설정한다.
- 데이터 수집 및 정제
- 독립변수(X, 특징)들을 수집한다.
- 데이터에서 이상치, 결측치 등을 정리하고 전처리한다.
- 데이터 탐색 및 시각화
- 수집한 데이터의 전체적인 구조와 특성을 파악한다.
- 그래프 등을 이용해 데이터의 분포나 패턴을 확인한다.
- 특징 선택 및 엔지니어링
- 모델이 잘 학습할 수 있도록 목표에 맞는 필요 특징(변수)만 선택한다.
- 기존 데이터에서 새로운 특징(특징엔지니어링 Feature Engineering)을 만들어 추가할 수도 있다.
- 모델 선택 및 학습
- 적절한 알고리즘(모델)을 선택한다.
- 데이터를 이용해 모델을 학습시킨다(Training).
- 모델 평가 및 개선
- 평가 지표(예: R-squared, 정확도, F1-score, RMSE 등)를 사용해 모델의 성능을 측정한다.
- 필요하면 모델을 튜닝(Hyperparameter tuning)하여 성능을 개선한다.
- 모델 배포 및 활용
- 최적화된 모델을 배포(Deployment)하여 실제 환경에서 사용한다.
- 지속적으로 새로운 데이터로 모델을 업데이트할 수도 있다.
규칙기반 인공지능 (Rule-Based AI)
- 특정 문제를 해결하기 위해 사람이 미리 정의한 규칙을 사용하여 동작.
- "이 조건이 참이면, 이 작업을 수행하라"와 같은 형식으로 규칙이 정의
- 복잡한 문제나 대규모 데이터에서의 유연성과 적응력이 부족
def is_spam(email_text):
spam_keywords = ["지금 구매", "한정 판매", "무료", "당첨", "여기를 클릭하세요"]
for keyword in spam_keywords:
if keyword.lower() in email_text.lower():
return True
return False
# 테스트
email1 = "축하합니다! 무료로 휴가에 당첨되셨습니다. 여기를 클릭하세요."
email2 = "안녕하세요, 지난주 회의에 대해 다시 연락드리고 싶었습니다."
print(f"이메일 1은 스팸입니까?: {is_spam(email1)}") # True
print(f"이메일 2는 스팸입니까?: {is_spam(email2)}") # False- 규칙기반으로 스팸 이메일을 필터링하는 예제.
- 특정 키워드가 포함된 이메일을 스팸으로 분류하는 규칙을 정의.
- 새로운 스팸 패턴이 등장하면 규칙을 수동으로 업데이트해야 한다는 단점이 있음.
학습기반 인공지능 (Learning-Based AI)
- 데이터를 통해 학습하여 스스로 규칙을 생성하고 예측을 수행.
- 머신러닝 모델이 데이터를 분석하고 패턴을 학습한 후, 새로운 데이터에 대한 결정을 내림.
- 나이브 베이즈 분류기를 사용한 스팸 메일 분류기
from sklearn.feature_extraction.text import CountVectorizer # 텍스트 데이터를 숫자로 변환하는 도구 (단어의 등장 횟수를 벡터로 변환)
from sklearn.naive_bayes import MultinomialNB # 다항 분포 나이브 베이즈 모델 (텍스트 분류에 자주 사용됨)
from sklearn.model_selection import train_test_split # 학습 데이터와 테스트 데이터를 분리하는 함수
from sklearn.metrics import accuracy_score # 모델의 예측 정확도를 평가하는 함수
# 샘플 데이터
emails = [
"지금 가입하면 첫 달 무료! 여기를 클릭하세요.",
"회의 자료를 첨부했습니다. 검토 부탁드립니다.",
"특별 할인 행사 중! 지금 바로 쇼핑하고 30% 할인 받으세요.",
"안녕하세요, 오늘 오후 회의 시간 확인 부탁드립니다.",
"당첨되셨습니다! 상품 수령을 위해 여기를 클릭하세요.",
"신규 프로젝트 투자 기회를 놓치지 마세요."
]
# 분류는 교사학습이니까 라벨이 있음
labels = [1, 0, 1, 0, 1, 1] # 1: 스팸, 0: 정상 이메일
# 데이터 전처리
# 벡터화 = 텍스트 데이터를 숫자로 변환
# X는 학습데이터
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(emails)
# 학습과 테스트 데이터로 분할
# X(학습데이터)와 Y(라벨)을 훈련데이터와 테스트데이터로 분할
# 테스트데이터가 20%, 훈련데이터가 80%
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2, random_state=42)
# 모델 학습 (나이브 베이즈 분류기)
model = MultinomialNB() # 다항식 나이브 베이즈
model.fit(X_train, y_train) # fit은 학습메서드
# 예측
# y_pred는 추정값
# 학습된 모델을 이용해 X_test 데이터를 예측하고, 결과를 y_pred에 저장
y_pred = model.predict(X_test)
# 정확도 평가
# 분류니까 모델신뢰도는 정확도(accuracy)로 측정
# y실제값 - y예측값이 0이 될수록 좋은 모델
# accuracy_score(y_test, y_pred)를 이용해 정확도를 계산
# y_test(y실제값)와 y_pred(y추정값)을 비교해서 정확도를 출력
accuracy = accuracy_score(y_test, y_pred)
print(f"정확도: {accuracy * 100:.2f}%")
# 새로운 이메일 예측
# 문자를 숫자로 바꾸는 벡터라이저 통해 데이터를 집어넣고 결과값 출력
# model.predict()를 이용해 스팸 여부 예측
new_email = ["이 기회를 놓치지 마세요! 특별 혜택이 기다리고 있습니다."]
new_email_transformed = vectorizer.transform(new_email)
print(f"새 이메일이 스팸입니까?: {model.predict(new_email_transformed)[0]}")| 단계 | 설명 |
| 1. 데이터 수집 | 이메일 텍스트와 라벨(스팸=1, 정상=0)을 준비 |
| 2. 데이터 전처리 | CountVectorizer로 텍스트를 숫자로 변환 (BoW) |
| 3. 데이터 분할 | train_test_split()로 학습용과 테스트용 데이터 분리 |
| 4. 모델 학습 | MultinomialNB()를 사용해 학습 |
| 5. 모델 평가 | accuracy_score()로 정확도 측정 |
| 6. 새로운 데이터 예측 | 새로운 이메일이 스팸인지 예측 |
※ 규칙기반과 학습기반 시스템의 장점을 결합한 혼합 시스템도 존재한다.
머신러닝(학습기반)
- 컴퓨터가 명시적으로 프로그래밍되지 않고도 데이터를 통해 학습하고 예측을 할 수 있게 하는 인공지능(AI)의 한 분야.
- 기계가 데이터를 분석하고 그 데이터로부터 패턴을 학습하여 새로운 데이터에 대해 유의미한 결정을 내릴 수 있도록 하는 것
머신러닝의 기본 개념
- 데이터(Training Data): 머신러닝 모델은 주로 데이터를 학습한다. 이 데이터는 입력과 출력의 쌍으로 이루어져 있으며, 모델이 패턴을 학습하는 데 사용된다. 예를 들어, 이미지 인식 모델의 경우, 각 이미지(입력)와 그 이미지가 나타내는 객체(출력)가 데이터 쌍을 이루게 된다.
- 특징(Features): 데이터를 모델에 입력할 때 중요한 정보는 특징(feature)으로 표현된다. 특징은 모델이 학습할 수 있는 형태로 데이터를 변환한 것이다. 예를 들어, 스팸 이메일 필터링 모델에서 이메일의 단어 빈도수는 중요한 특징이 될 수 있다.
- 모델(Model): 모델은 데이터를 입력으로 받아 패턴을 학습한 후, 새로운 데이터를 입력받았을 때 예측을 할 수 있도록 하는 수학적 구조이다. 다양한 알고리즘을 사용해 모델을 구축할 수 있다.
- 학습(Learning): 학습이란 모델이 데이터를 통해 패턴을 찾아내고 이를 바탕으로 새로운 데이터에 대한 예측을 가능하게 만드는 과정이다. 학습은 일반적으로 지도학습(Supervised Learning), 비지도학습(Unsupervised Learning), 강화학습(Reinforcement Learning)으로 나눌 수 있다.
- 손실 함수(Loss Function): 모델의 예측이 얼마나 정확한지를 평가하는 척도이다. 손실 함수는 모델이 예측을 얼마나 잘했는지를 수치화하여 나타내며, 모델 학습 과정에서 이 값을 최소화하려고 노력한다.
- 손실 함수의 개념
- 목적: 손실 함수는 예측 값과 실제 값 사이의 오차를 측정한다. 이 오차를 최소화하는 방향으로 모델의 파라미터를 업데이트하여 학습을 진행한다.
- Y실제값 - Y예측값 = Error
- 역할: 손실 함수의 출력 값이 작을수록 모델의 예측이 정확하다는 것을 의미한다. 반대로, 손실 값이 크다면 모델의 예측이 부정확하다는 것을 나타낸다.
- RMSE가 가장 많이 쓰인다.
- 목적: 손실 함수는 예측 값과 실제 값 사이의 오차를 측정한다. 이 오차를 최소화하는 방향으로 모델의 파라미터를 업데이트하여 학습을 진행한다.
- 손실 함수의 개념
# 대표적인 손실 함수
- 평균 제곱 오차 (Mean Squared Error, MSE) - 가장 많이 씀.
- 정의 : MSE는 회귀 문제에서 자주 사용되는 손실 함수로, 예측 값과 실제 값 간의 차이를 제곱하여 평균한 값.
- 특징 : 오차의 제곱을 사용하기 때문에 큰 오차에 대해 더 큰 페널티를 부여.
- 수식 :

- 로지스틱 손실 (Logistic Loss, Cross-Entropy Loss)
- 정의 : 이진 분류 문제에서 자주 사용되는 손실 함수로, 모델의 예측 확률과 실제 라벨 간의 차이를 측정.
- 특징 : 확률 예측에서 잘못된 예측에 대한 페널티를 부여.
- 수식 :
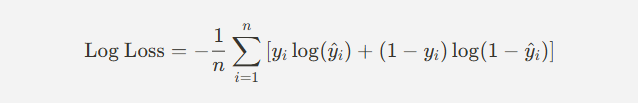
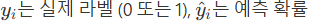
- 절대 오차 (Mean Absolute Error, MAE) - 잘 안씀.
- 정의 : MAE는 예측 값과 실제 값의 차이의 절대값을 평균한 값.
- 특징: 오차의 크기에 관계없이 일정한 페널티를 부여하며, MSE보다 이상치에 덜 민감.
- 수식 :
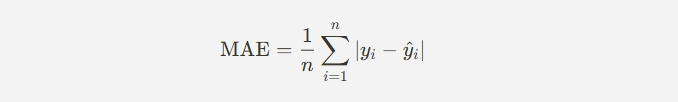
- MSE 수식을 전개하면 아래와 같은 2차식이 나오며 2차 함수를 그래프로 표현하면 아래와 같다.
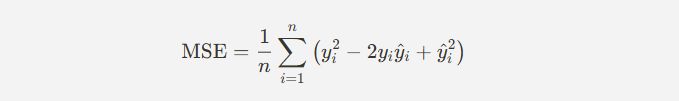
※ MSE식을 2차식으로 만들기 위해 전개시킴 = MSE를 풀어서 2차 함수 형태로 바꾼다는 것. MSE를 2차식으로 전개하는 이유는 미분을 쉽게 해서 최적화 과정에 활용하기 위해서이다. 이걸 통해 실제 머신러닝에서 경사 하강법 같은 최적화 방법을 쓸 때 더 쉽게 계산할 수 있음.
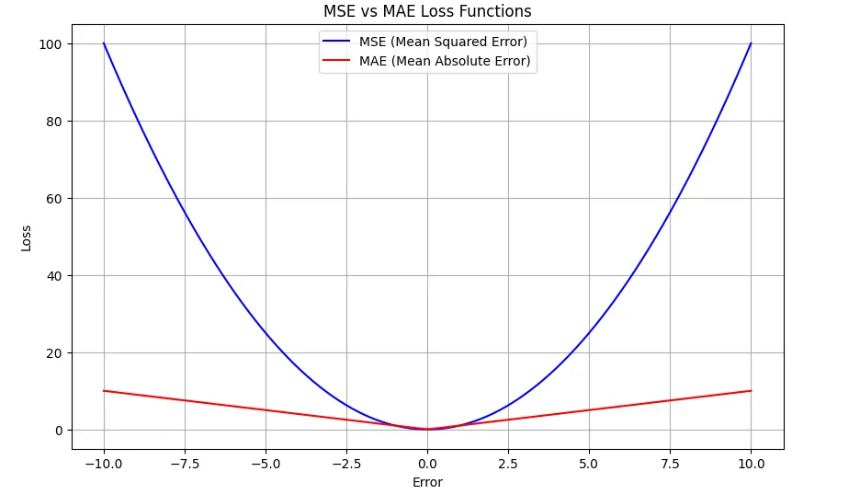
0.0 → 옵티멀 포인트(optimal point). 최적의 지점. 모델이 가장 잘 동작하는 파라미터 값들이나, 또는 손실 함수가 최소가 되는 지점을 의미. 최적화된 성능을 낼 수 있는 가장 좋은 지점.
6. 최적화(Optimization): 손실 함수를 최소화하기 위해 모델의 파라미터를 조정하는 과정. 흔히 사용하는 최적화 방법으로는 경사 하강법(Gradient Descent)이 있다.

# 경사 하강법 - 최적값을 찾기 위해 기울기를 계속 바꾼다!!
- 함수의 최소값을 찾기 위한 최적화 알고리즘.
- 주로 머신러닝에서 손실 함수의 최소값을 찾아 모델의 파라미터를 최적화하는 데 사용.
- 반복적으로 함수의 기울기(경사)를 계산하고, 그 기울기의 반대 방향으로 이동하면서 함수 값을 점차 감소시킨다.
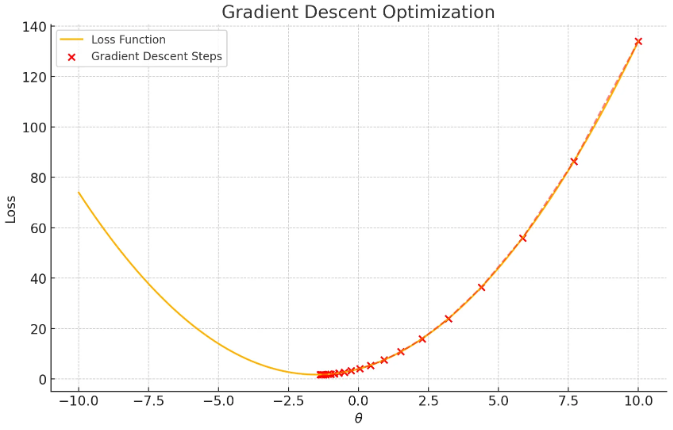
머신러닝의 주요 알고리즘
- 회귀(Regression): 연속적인 값을 예측하는 모델. 예를 들어, 주택 가격을 예측하는 모델이 회귀 모델에 해당.
- 의사결정나무(Decision Trees): 데이터를 분류하는데 사용하는 트리 구조의 모델. 분류 작업에 자주 사용.
- 서포트 벡터 머신(SVM, Support Vector Machines): 데이터를 고차원 공간으로 변환하여 두 클래스 간의 경계선을 찾는 분류 알고리즘.
- 인공신경망(Artificial Neural Networks): 인간의 뇌 구조를 모방한 모델로, 여러 층(layer)을 사용해 복잡한 패턴을 학습. 특히 딥러닝(deep learning)에서 널리 사용.
- k-평균 군집화(k-means Clustering): 데이터를 k개의 군집으로 나누는 비지도학습 알고리즘.
머신러닝의 작업유형
# 분류 (Classification)
- 정의: 주어진 입력 데이터를 미리 정의된 여러 클래스 중 하나로 분류하는 작업.
- 출력: 이산적(범주형) 값.
- 예시: 이메일 스팸 필터링(스팸/정상), 이미지 분류(고양이/개).
# 회귀 (Regression)
- 정의: 입력 데이터에 대한 연속적인 값을 예측하는 작업.
- 출력: 연속적(실수형) 값.
- 예시: 주택 가격 예측, 온도 예측.
# 군집화 (Clustering)
- 정의: 데이터를 유사한 특성을 가진 그룹으로 묶는 작업. 사전 정의된 클래스 없이 데이터 내의 구조를 발견.
- 출력: 군집(클러스터) 그룹.
- 예시: 고객 세분화, 문서 군집화. 압축
# 차원 축소 (Dimensionality Reduction) - 비지도 학습
- 정의: 고차원 데이터를 더 적은 수의 중요한 차원으로 변환하는 작업. 데이터의 핵심 정보를 보존하면서 차원을 축소.
- 출력: 축소된 차원으로 표현된 데이터.
- 예시: 데이터 시각화(PCA), 노이즈 제거.
# 강화 학습 (Reinforcement Learning)
- 정의: 에이전트가 환경과 상호작용하며 보상을 최대화하는 방향으로 학습하는 작업. 에이전트는 다양한 행동을 시도하면서 보상 피드백을 통해 최적의 정책을 학습.
- 출력: 최적의 행동 정책.
- 예시: 자율주행 차량, 게임 플레이 AI.
# 이상 탐지 (Anomaly Detection) - 비지도학습
- 정의: 데이터에서 정상 패턴과 다르게 보이는 이상 패턴(이상치)을 식별하는 작업.
- 출력: 정상/이상 여부 또는 이상 점수.
- 예시: 금융 사기 탐지, 기계 고장 예측.
머신러닝 알고리즘 지도 학습의 수학적 표현
- 지도 학습의 핵심 목표는 입력 데이터 X와 출력 Y사이의 함수 f를 학습하는 것.
- 이 함수는 주어진 새로운 입력 (X)에 대해 예측된 출력 (Y)을 생성하는 데 사용.

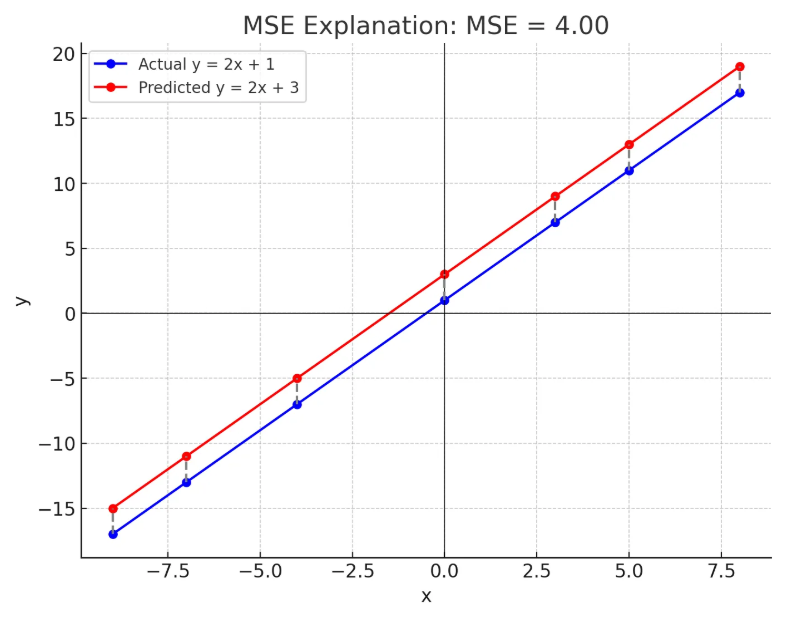
모델은 손실 함수(Loss Function)를 최소화하도록 학습된다. 손실 함수는 모델의 예측 값과 실제 값 사이의 차이를 측정하는 함수로, 예를 들어 선형 회귀의 경우 평균 제곱 오차(MSE, Mean Squared Error)는 다음과 같이 정의된다.
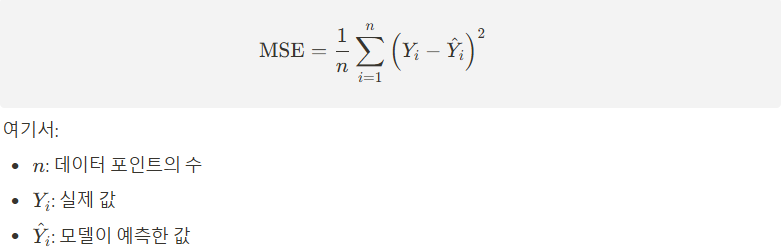

※ Y실제값 = [8, 9, 7, 6, 5] 이고 Y예측값 = [7 ,8, 8 ,7, 9] 일때 손실함수를 구해라.
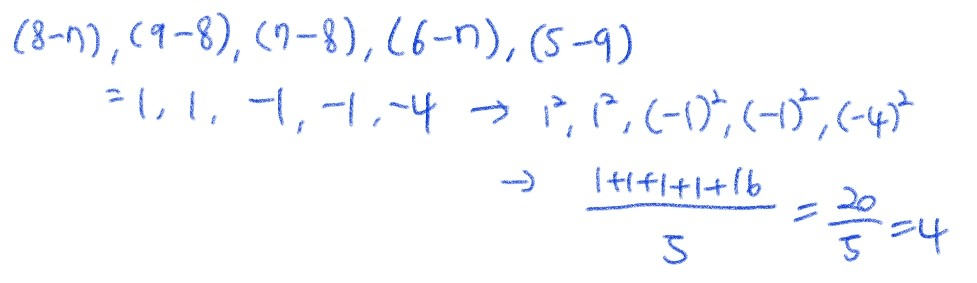
로지스틱 회귀를 사용하여 텍스트 데이터를 감성 분석하는 분류 모델을 학습하는 코드
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
# 샘플 데이터 (긍정: 1, 중립: 2, 부정: 3) - 데이터 개수 증가 (30개)
emails = [
# 부정 (3) - 스팸성 광고
"지금 가입하면 첫 달 무료! 여기를 클릭하세요.",
"당첨되셨습니다! 상품 수령을 위해 여기를 클릭하세요.",
"무료 쿠폰이 도착했습니다. 클릭하여 혜택을 받으세요!",
"축하합니다! 특별 할인 혜택을 드립니다.",
"당신의 계정이 정지될 예정입니다. 지금 확인하세요.",
"긴급: 보안 문제로 인해 계정을 업데이트해야 합니다.",
"최고의 할인 혜택! 지금 구매하세요.",
"신용카드 혜택이 변경되었습니다. 확인해보세요.",
"은행 계좌 정보 확인이 필요합니다. 클릭하세요.",
"이메일 비밀번호를 재설정해야 합니다. 지금 확인하세요.",
# 중립 (2) - 일반적인 업무 이메일
"회의 자료를 첨부했습니다. 검토 부탁드립니다.",
"안녕하세요, 오늘 오후 회의 시간 확인 부탁드립니다.",
"다음 주 일정 조정이 필요합니다. 회신 부탁드립니다.",
"회사 정책이 변경되었습니다. 첨부된 내용을 확인해 주세요.",
"주간 업무 보고서 초안을 공유드립니다.",
"다음 분기 마케팅 전략 회의가 예정되어 있습니다.",
"사내 시스템 점검 일정이 업데이트되었습니다.",
"신규 프로젝트 일정이 확정되었습니다. 확인 부탁드립니다.",
"급여 명세서가 발송되었습니다. 확인해주세요.",
"출장 요청이 승인되었습니다. 관련 서류를 제출해주세요.",
# 긍정 (1) - 긍정적인 마케팅 및 추천 메시지
"특별 할인 행사 중! 지금 바로 쇼핑하고 30% 할인 받으세요.",
"신규 프로젝트 투자 기회를 놓치지 마세요.",
"새로운 패션 트렌드, 지금 쇼핑하세요!",
"기다리던 신제품이 출시되었습니다. 지금 확인하세요!",
"최고의 영화 추천! 지금 시청하세요.",
"건강한 식습관을 위한 맞춤형 식단을 확인하세요.",
"이 주의 베스트셀러 도서를 추천드립니다.",
"인공지능이 추천하는 맞춤형 뉴스! 지금 확인하세요.",
"이번 주 인기 여행지를 확인하세요!",
"나만을 위한 맞춤형 운동 계획을 받아보세요."
]
# 분류는 지도학습이니까 라벨이 있음.
labels = [3] * 10 + [2] * 10 + [1] * 10 # 1: 긍정, 2: 중립, 3: 부정 (각 10개씩 균등 분포)
# 데이터 벡터화 (CountVectorizer 사용)
# 벡터화 = 숫자화시킨다.
# X는 학습데이터
vectorizer = CountVectorizer() # CountVectorizer 객체 생성
X = vectorizer.fit_transform(emails) # 이메일 데이터 학습을 위해 벡터화
# 학습 & 테스트 데이터 분할
# X(학습데이터)와 Y(라벨)을 훈련데이터와 테스트데이터로 분할
# 테스트데이터가 30%, 훈련데이터가 70%
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.3, random_state=42, stratify=labels)
# 모델 학습 (Logistic Regression)
model = LogisticRegression(max_iter=300) # 로지스틱 회귀모델 생성
model.fit(X_train, y_train) #fit : 학습메서드 # 모델 학습
# 예측
#y_pred는 추정값
y_pred = model.predict(X_test) # 테스트 데이터로 예측
# 정확도 평가
# 분류니까 모델신뢰도는 정확도(accuracy)로 측정
# y실제값 - y예측값이 0이 될수록 좋은 모델
accuracy = accuracy_score(y_test, y_pred) # 테스트 데이터와 예측 데이터로 모델 정확도 평가
print(f"정확도: {accuracy * 100:.2f}%")
# 분류 보고서 (zero_division=1로 설정하여 경고 제거)
print("\n분류 보고서:")
print(classification_report(y_test, y_pred, target_names=["긍정", "중립", "부정"], labels=[1, 2, 3], zero_division=1))
# 새로운 이메일 예측
# 문자를 숫자로 바꾸는 벡터라이저 통해 데이터를 집어넣고 결과값 출력
new_email = [
"회의 자료를 검토해 주세요.",
"이번 주 인기 도서를 추천드립니다."
]
new_email_transformed = vectorizer.transform(new_email) # 새로운 이메일 데이터 백터화
predicted_labels = model.predict(new_email_transformed) # 새로운 이메일 데이터 예측
# 결과 출력
label_map = {1: "긍정", 2: "중립", 3: "부정"}
for email, label in zip(new_email, predicted_labels):
print(f"이메일: \"{email}\" → 감성 분석 결과: {label_map[label]}")
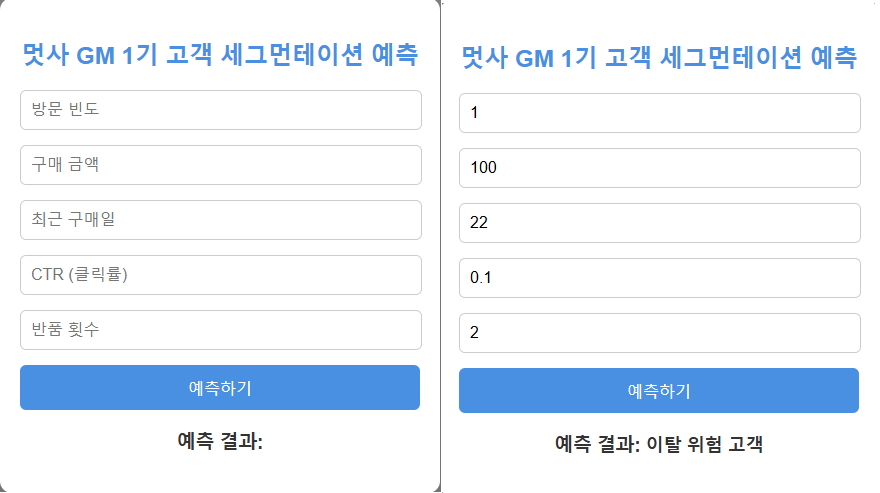
로지스틱 회귀 코드를 웹으로 구현하는 실습
- 로지스틱 회귀를 이용해 고객 세그멘테이션을 하는 코드
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, classification_report
# 고객 데이터 (그로스 마케팅 성과지표)
data = pd.DataFrame([
[5, 1000, 2, 0.05, 0, 1], # VIP 고객
[3, 700, 7, 0.02, 1, 2], # 일반 고객
[1, 100, 30, 0.01, 2, 3], # 이탈 위험 고객
[4, 900, 3, 0.04, 0, 1], # VIP 고객
[2, 300, 15, 0.03, 1, 2], # 일반 고객
[1, 50, 40, 0.005, 3, 3], # 이탈 위험 고객
[5, 1200, 1, 0.06, 0, 1], # VIP 고객
[3, 600, 10, 0.025, 1, 2], # 일반 고객
[2, 200, 20, 0.015, 2, 3], # 이탈 위험 고객
[4, 800, 5, 0.045, 0, 1], # VIP 고객
[3, 650, 8, 0.022, 1, 2], # 일반 고객
[1, 120, 35, 0.008, 3, 3], # 이탈 위험 고객
[5, 1300, 1, 0.065, 0, 1], # VIP 고객
[2, 250, 22, 0.018, 2, 3], # 이탈 위험 고객
[3, 750, 6, 0.03, 1, 2], # 일반 고객
[4, 850, 4, 0.04, 0, 1], # VIP 고객
[1, 90, 38, 0.007, 3, 3], # 이탈 위험 고객
[2, 280, 17, 0.02, 2, 2], # 일반 고객
[5, 1400, 2, 0.07, 0, 1], # VIP 고객
[3, 720, 9, 0.025, 1, 2] # 일반 고객
], columns=["방문 빈도", "구매 금액", "최근 구매일", "CTR", "반품 횟수", "고객 세그먼트"])
# 입력(X) / 출력(y) 데이터 설정
X = data.drop(columns=["고객 세그먼트"]) # 특징 데이터
y = data["고객 세그먼트"] # 레이블 (VIP, 일반, 이탈 위험 고객)
# 데이터 표준화 (스케일링) → DataFrame 유지하여 경고 방지
scaler = StandardScaler()
X_scaled = pd.DataFrame(scaler.fit_transform(X), columns=X.columns)
# 학습 & 테스트 데이터 분할 (70% 학습, 30% 테스트)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42, stratify=y)
# 로지스틱 회귀 모델 학습 (multi_class 제거하여 경고 방지)
model = LogisticRegression(solver='lbfgs', max_iter=500)
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# 정확도 평가
accuracy = accuracy_score(y_test, y_pred)
print(f"정확도: {accuracy * 100:.2f}%")
# 분류 보고서
print("\n 고객 세그먼테이션 성능 평가:")
print(classification_report(y_test, y_pred, target_names=["VIP 고객", "일반 고객", "이탈 위험 고객"]))
# 새로운 고객 데이터를 입력하여 예측
new_customers = pd.DataFrame([
[4, 950, 3, 0.05, 0], # 예상: VIP 고객
[2, 250, 25, 0.02, 1], # 예상: 일반 고객
[1, 80, 35, 0.008, 3] # 예상: 이탈 위험 고객
], columns=["방문 빈도", "구매 금액", "최근 구매일", "CTR", "반품 횟수"])
# 데이터 표준화 후 예측 (DataFrame 유지)
new_customers_scaled = pd.DataFrame(scaler.transform(new_customers), columns=new_customers.columns)
predicted_segments = model.predict(new_customers_scaled)
# 세그먼트 매핑
segment_labels = {1: "VIP 고객", 2: "일반 고객", 3: "이탈 위험 고객"}
# 예측 결과 출력
print("\n 신규 고객 세그먼테이션 예측:")
for i, segment in enumerate(predicted_segments):
print(f"신규 고객 {i+1}: {segment_labels[segment]}")
GCP에서 VM인스턴스의 터미널에 접속 후 리눅스 명령어로 폴더를 만들고 권한을 부여한다.
파일질라로 zip의 각 파일을 폴더로 옮긴다.
html 파일은 templates폴더에, css 파일은 static 폴더에, app.py는 templates, static의 상위 폴더에 위치시킨다.
python3 app.py로 실행하고 웹에서 http://vm외부ip주소:포트번호 로 들어가서 확인한다.
※ 아래와 같이 모듈 미설치 오류가 나면 해당 모듈을 설치해주면 된다.
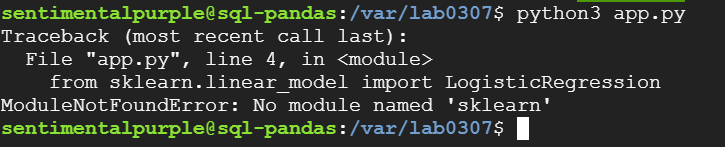
☞ pip install scikit-learn 입력 후 설치해 주면 완료
주어진 코드를 바꾸어서 실습해보기도 하였다.
맛나 분식집 고객 유형을 분석하기 위해 고객을 '단골 고객, 일반 고객, 홍보가 필요한 고객'으로 분류하고 분류하는 기준은 '방문 횟수, 구매 금액, 긍정 리뷰 횟수'로 정했다.

'데이터 분석 part' 카테고리의 다른 글
| 모델 성능 평가와 다중 분류 / 결정 트리의 기본 개념 / 랜덤 포레스트 개념과 구현 (0) | 2025.03.11 |
|---|---|
| 데이터 전처리, 특징 엔지니어링, 선형회귀, 로지스틱회귀 (0) | 2025.03.11 |
| 웹서버로 보고서 구현(flask) / 루커 스튜디오 실습 및 데이터 소스 연결 (0) | 2025.03.06 |
| * 태블로 실습 / Chart.js를 이용한 웹페이지 실습 (0) | 2025.03.06 |
| Tableau 기본 사용법 (1) | 2025.03.05 |